MySQL 2판을 보던 중 한가지 사실을 알았다. 바로 WHERE 조건문에 INDEX 를 통해서 검색하려고 할때 INDEX 에 변환 또는 연산을 가하게 될 경우 인덱스 조건을 안타게 된다는 사실이다. 아래 쿼리를 한번 보자.
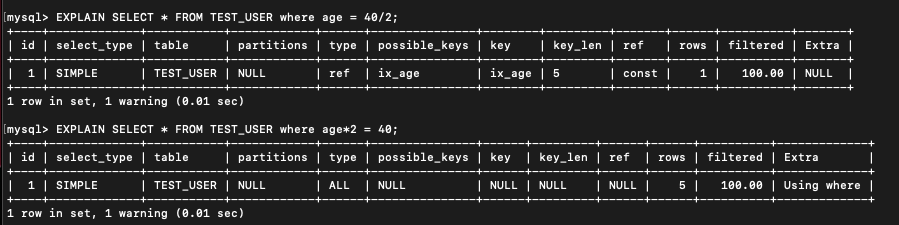
지금 위의 쿼리를 한번 살펴보면 첫번째 쿼리는 age 라는 INDEX 컬럼에 2를 곱한 뒤 age=20 인 컬럼의 데이터를 가져오는 쿼리이다. 두번째 쿼리는 반대로 age = 40/2 인 즉 age = 20 인 쿼리를 가져오는 것이므로 두 쿼리의 결과는 아래처럼 똑같다.

하지만 결과는 같은데 MySQL 의 옵티마이저가 내린 판단은 다르다.
그 이유는 무엇일까?
MySQL 에서는 기본적으로 정렬에 B-Tree 자료구조를 이용하는데 이때 사용자가 설정한 Index 의 값으로 정렬이 되어 있을 것이다. 그런데 여기서 Index 를 가공하는 쿼리를 날리게 되면 정상적으로 INDEX 를 사용해야 하는지 옵티마이저가 판단할 수 없다. 컬럼을 하나하나 가공(연산) 한 후 비교연산을 수행해야 하기 때문이다. 아래는 위와 같은 상황으로 타입변환이 일어나게 쿼리를 작성해도 인덱스를 타지 않을 수 있다는 결과를 보여준다.
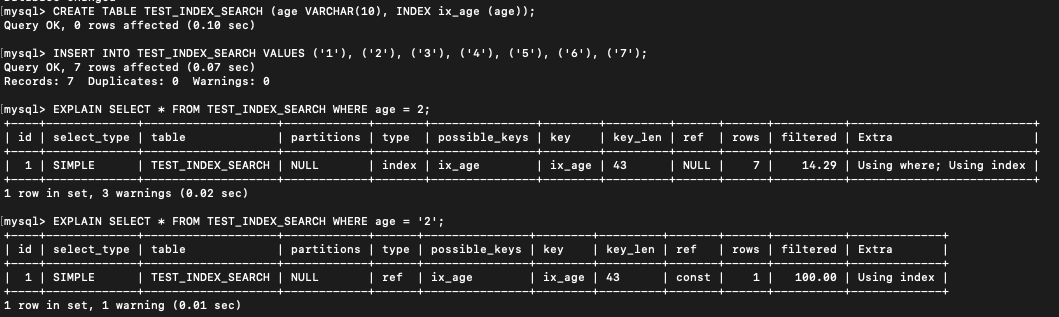
왜 '2' 로 했을때는 인덱스가 잘 타지는데 2 로 했을 경우에는 잘 타지지 않을까?
아까 위에서 설명했듯이 "INDEX 에 특정 연산 혹은 변환이 가해질 경우에는 INDEX 레인지 스캔을 이용하지 못할 수 있다" 인데, MySQL 내부적으로 "SELECT * FROM TEST_INDEX_SEARCH WHERE age = 2" 쿼리의 경우에는 VARCHAR 타입을 INTEGER 타입으로 변환한 후 비교작업을 수행해야 하기 때문에 위와 같은 수행결과의 차이를 보이게 되는 것이다.
'데이터베이스' 카테고리의 다른 글
| Redisson 을 분산 Lock 을 위해 사용한 이유 (0) | 2022.02.12 |
|---|