최근 팀에 SlowQuery 개선으로 인덱스를 추가하면서 쓸모없는 인덱스가 겹치는 인덱스들이 있겠다는 생각이 들었다. 그래서 팀원들과 같이 얘기해보고 DBA 분과도 얘기해봤지만 마땅한 방법을 찾지 못했었다. 그래서 처음에는 General log 떨어지는 것들을 조사해보는 프로그램 이런걸 만들어볼까? 하다가 이건 미친짓이다 싶어서 분명히 방법이 있을거야 하고 검색을 해보게 됬다. MySQL 을 공부하다보면 알게 되는것이 성능 분석을 위해서는 performance_schema 를 확인하는 것이 가장 좋다.
일단 MySQL 공식문서에도 나와 있듯이, performance_schema 테이블은 information_schema 보다 좀 더 low 한 level 에서의 측정을 기반으로 성능측정을 하게 된다. 성능스키마는 대부분 Event 를 기반으로 이뤄지는 부분이 많다. 그래서 내가 쿼리를 날릴때 그 쿼리를 날리는 이벤트에 대한 정보들에 대한 metric 을 얻을 수 있게 된다. 다만 그래서 그러면 성능이 저하되는건 아니야? 라는 생각도 들었는데, 다행히 MySQL 공식문서를 보면 아래와 같이 설명하며 그런 부분들은 걱정은 하지 않아도 되. 라고 말한다.

실습
일단 넘어가서 이제 직접적으로 옵션을 키면서 적용해보자.
(사실 이런말하면 그런데 블로그 글 적는 빈도가 줄은게, 회사 위키로 적는건 회사 코드를 적어놔도 되서 쉬운데 블로그에 적자니 회사 코드도 예제로 못쓰고 이러니 내가 직접 예제를 만들어야 되는데 그게 너무 부담이다..)
show variables like 'performance_schema';위의 쿼리를 날려보고 만약 OFF 로 되어 있다면 켜주도록 하자. performance_schema 는 dynamin parameter 가 아니여서 반드시 DB 를 재부팅 해주어야 하는 것으로 알고 있다. DB conf 파일에 아래와 같이 설정값을 넣어두고, DB 를 재부팅하자
performance_schema = ON
우리가 필요한 옵션은 아래와 같다.
update performance_schema.setup_consumers set enabled = 'yes' where name = 'events_waits_current';
update performance_schema.setup_instruments set enabled = 'yes' where name = 'wait/io/table/sql/handler';일단 'event_waits_current' 테이블을 한번 보자
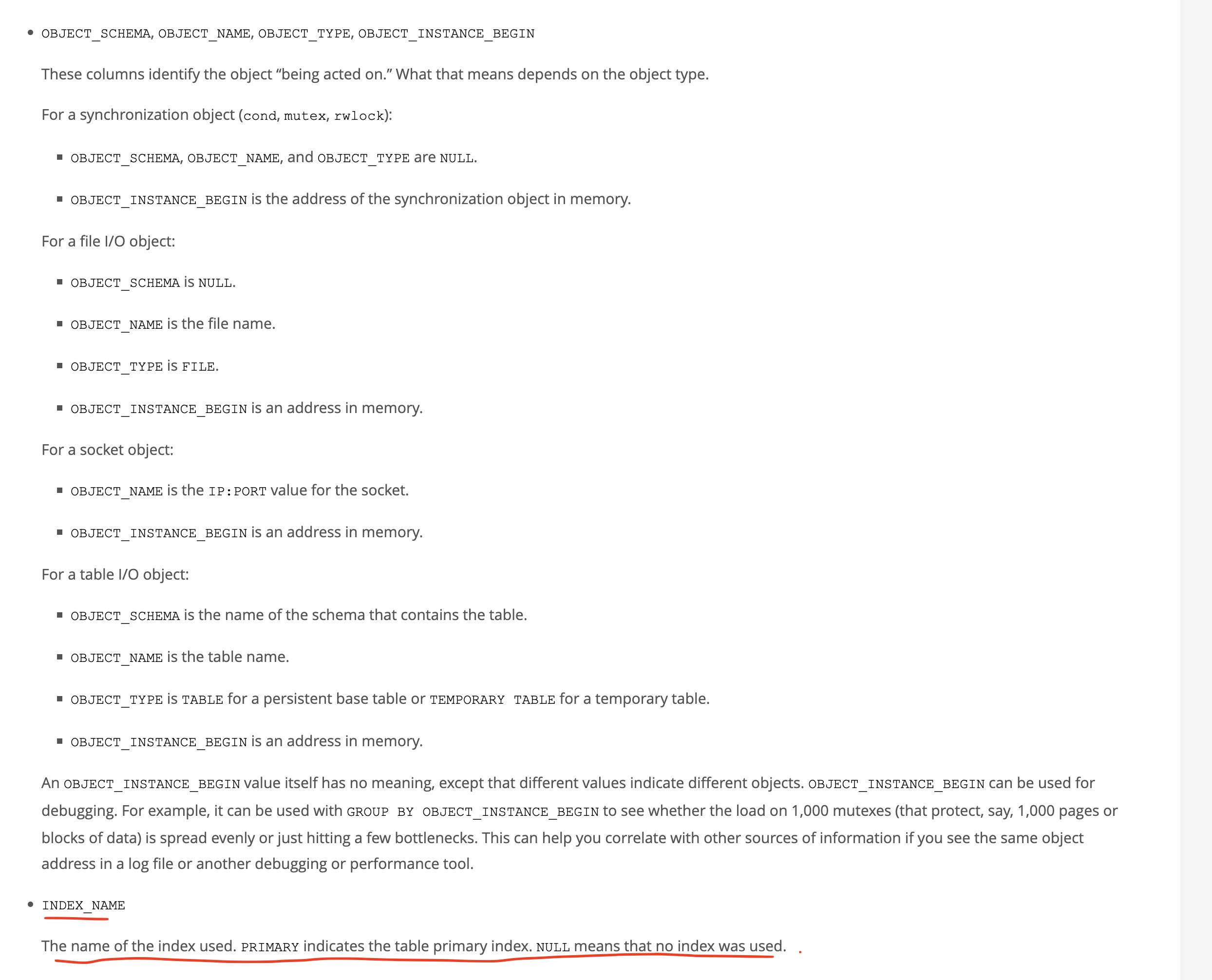
이 테이블에는 많은 정보가 있지만 우리에게 필요한 정보는 INDEX_NAME 이라고 보면 된다.
wait/io/table/sql/handler
그리고 이 옵션이 가장 중요한데, 이걸 키게 되면 I/O 와 관련된 모든 이벤트를 수집한다.그리고 가장 중요한것이 아래의 테이블을 만들어주게 된다. table_io_waits_summary_by_index_usage 이 테이블이 사실상 우리가 INDEX 관련된 지표를 보는데 사용할 테이블이다.

위에 콜럼들을 보면 알겠지만 COUNT_STAR, INDEX_NAME 중 쓸만한 지표들이 많이 보인다.
쿼리 실행
SELECT
object_schema as db_name,
objcet_name as table_name,
index_name
FROM performance.schema.table_io_waits_summary_by_index_usage
WHERE index_name IS NOT NULL
AND index_name != 'PRIMARY' # 주키는 볼필요없어서 제외했음
AND count_start = 0
AND object_schema = 'table_name'
ORDER BY object_schema, object_name위와 같이 쿼리를 날리면 미사용 인덱스를 조회할 수 있다. 우리도 이 과정을 통해 주테이블의 사용하지 않는 인덱스를 많이 제거했다. 또 알아봤던 쿼리는 아래 쿼리이다. 근데 둘다 같은 방식인걸로 알고 있다. schema_unused_indexes 테이블도 결국 table_io_waits_summary_by_index_usage 를 이용한다는 것 같았다.
SELECT * FROM sys.schema_unused_indexes;
후기
요즘 DB 관련 작업들을 어쩌다보니 팀내에서 많이 하고 있는데, 꽤 도움이 많이 된다. Real MySQL 을 또 한번 정주행 하면서 정리할까? 최근 고민중이긴하다. 뭔가 DBA 분들과 스터디를 나중에 해보고 싶기도 하다. 다만 너무 부족해서 민폐겠지만 ㅎㅎ 많이 배울수 있지 않을까? 이런생각을 많이 한다.
'DB' 카테고리의 다른 글
| MySQL Hint (0) | 2022.05.09 |
|---|